



L'agent IA Deep Research : recherche avancée et automatisée
vers le bullshit automatisé ?

Hello à tous,
Bienvenue dans cette 46ᵉ édition !
Vous pouvez cliquer sur le ❤️ au-dessus ou en fin de newsletter si vous appréciez le contenu, ça m’aide beaucoup ! 🙏
Voici le sommaire de la semaine :
💼 Zoom sur le cas concret de la recherche automatisée
🗞️ 3 actus importantes : o3 d’OpenAI, Rapport IA McKinsey, Gemini 2.0
⏳ Temps de lecture : 10 min
💼 Zoom sur le cas concret de la recherche automatisée
La recherche automatisée : un enjeu majeur
Chaque jour, nous passons entre 10 et 30% de notre temps à rechercher des informations. Une perte de temps énorme, surtout quand on sait que la plupart de ces recherches suivent un schéma bien défini :
Identification du sujet
Recherche des mots-clés pour structurer notre requête sur les moteurs de recherche
Exploration, lecture, analyse d’informations via des sources fiables.
Agrégation et organisation pour compiler les données essentielles.
Synthèse et rédaction avec génération d’un contenu structuré.
Avec l’IA, ces étapes peuvent être toutes automatisées pour gagner en efficacité et en précision. Et c’est d’ailleurs dans ces domaines où la techno est assez mature : récupérer des informations en masse, les analyser, les structurer.
Ces étapes, qui prenaient parfois des jours, peuvent désormais être réalisées en une dizaine de minutes avec la combinaison d’un modèle IA avancé et d’outils à sa disposition. Et derrière, il y a plein de cas d’usages :
Veille concurrentielle → analyser la position de ses concurrents, leurs offres, leurs produits, leurs forces et faiblesses.
Études de marché → collecter et recouper des données sectorielles, évaluer le positionnement, l’évolution des tendances.
Conseils personnalisés → proposer des recommandations, des pistes d’amélioration, ou anticiper des opportunités d’investissement.
Ce n’est pas nouveau, car on gagnait déjà beaucoup de temps avec des outils comme Perplexity. Mais là on va quand même plus loin.
L’arrivée de Deep Research d’OpenAI : un agent autonome de recherche
OpenAI a récemment partagé sa nouvelle fonctionnalité Deep Research, un agent capable de naviguer sur le web pour effectuer des recherches et organiser les résultats en un temps record. Ils annoncent : “le système parcourt, en quelques minutes, ce qui pourrait nous prendre plusieurs heures.”

Un point marrant est qu’OpenAI a voulu partager le gain économique par rapport à un travail humain. Mais il n’est pas simple de relier directement le gain économique avec le temps passé par un humain. Car le temps nécessaire pour un humain sur certaines tâches est parfois plus rapide qu’un agent IA, comme le montre cette courbe.

L’agent Deep Research utilise :
Un modèle de raisonnement d’OpenAI : o3, o1, ...
Un “Agentic framework” : un environnement où l’IA s’organise en étapes, utilise des outils dédiés (navigation web, exécution de code, etc.) et planifie méthodiquement son raisonnement.
La capacité à exécuter du code (souvent Python) pour analyser les données, tout en s’appuyant sur des méthodes de raisonnement multi-étapes (Chain-of-Thought).
Concrètement, Deep Research sait parcourir des sites, consolider les informations récoltées, structurer un rapport complet (résumés, listes, tableaux, citations) et répondre aux questions complexes nécessitant, par exemple, plusieurs requêtes et recoupements.
Voici l’aperçu d’un résultat :

Un risque de “Bullshit” automatisé ?
Recherche du contenu web en automatique pour le résumer, ce n’est pas nouveau. C’est ce que font des outils comme Perplexity, searchGPT sur l’interface chatGPT. Là, la différence se joue dans les itérations du modèle pour continuer d’aller chercher la bonne information.
⚠️ ⚠️⚠️ Et il y a un risque non négligeable de désinformation : l’outil peut donc récupérer du contenu incorrect, l’analyser et venir nourrir le résumé initial. Sans un esprit critique avancé et une bonne connaissance du sujet, il sera difficile d’identifier les points de détail incorrects.
En plus, ce résumé pourrait être publié en ligne, créant une boucle vicieuse où d’autres modèles vont récupérer ce contenu incorrect, etc (voir l’effondrement des modèles). Et cela pourrait impacter les papiers de recherche, les rapports que l’on peut nous même consulter…
Une des solutions possibles serait de contraindre le modèle à baser les recherches uniquement sur des sources fiables (du “premium-content”). Dans le cas de Deep Research, on n’a pas toutes les informations sur son fonctionnement, difficile de juger.
Mais gardez en tête de vérifier et d’auditer les contenus critiques, surtout en contexte professionnel.
L’approche “Agent” : pourquoi ça change la donne
Lorsqu’on parle de recherche automatisée, le point clé n’est pas seulement l’accès à un gros modèle de langage. Ce qui fait la différence, c’est l’approche dite agentique (“Agentic Framework”). Un agent IA n’est pas un chatbot passif qui se contente de répondre à une requête. Il est capable :
De planifier des actions : “d’abord, chercher des infos sur tel site, puis lancer un script Python pour analyser les données, ensuite comparer avec une autre source, etc.”
De s’adapter en temps réel en fonction des résultats (nouvelles pistes, changement de mot-clé, recherche d’alternatives).
De séparer sa réflexion interne (Chain-of-Thought) de ses actions effectives (requêtes de recherche, code, etc.), limitant les confusions.
C’est un saut qualitatif majeur. Le fait de coder cette démarche dans un schéma d’agent améliore grandement les résultats.
Par exemple, voici les scores sur le benchmark GAIA :

Et maintenant avec l’approche d’OpenAI en mode agent :

Pourquoi maintenant ?
Ce qui fait que l’on est à tournant sur beaucoup de cas concrets en entreprises, c’est la maturité des modèles de language. Concrètement :
Ils sont plus puissants
Il est possible de les entrainer sur une tâche spécifique comme la recherche (via du fine-tuning)
L’apprentissage des modèles (reinforcement learning) pour avoir de meilleurs résultats est mieux maitrisée.
Cette maturité, combinée à un coût qui baisse, fait qu’il est maintenant rentable de laisser un agent IA faire des recherches complexes plutôt que de mobiliser un humain.
Les alternatives possibles (et open source)
Deep Research est un outil extrêmement performant, mais il est cher, très cher, à 200$/mois. Alors tout cela repose grosso modo sur :
“Raisonner, rechercher, exécuter du code, résumer, raisonner, rechercher etc”
Il existe déjà des briques équivalentes en open source, parfois moins puissantes sur certains points, mais gratuites (ou très peu onéreuses). Voici en vrac des exemples open-source qui sont possibles :
Jina Node Research: c’est ce que j’ai utilisé pour la vidéo plus bas. Avec un peu de configuration, on peut créer des pipelines d’IA capables de parcourir et d’indexer des documents avant de répondre aux questions.

J’avais déjà présenté cet outil dans mon process de création de contenu automatisé pour visiter des URLs, récupérer le contenu dans un format structuré et les partager à un modèle.

d’autres solutions que j’ai vues passer sur X, Open Deep Research ou celle-ci
Bref, vous pouvez déjà constituer vos propres agents pour presque rien, en mettant un peu les mains dans le cambouis. Ces systèmes se basent sur la même logique : découper la tâche, parcourir du contenu en ligne, synthétiser de façon structurée.
Voici une rapide démo de ce que ça donne sur une requête “étude de marché sur l’impact de l’IA au travail”
Comment améliorer vos résultats ?
On peut déjà avancer sur ce sujet, mais il est aussi nécessaire d’y aller par étape. Si l’on s’attaque à un sujet aussi large et complexe que la génération d’une étude de marché de A à Z, ça va être compliqué.
Le plus simple est donc de découper les étapes qui permettent d’arriver au résultat final. Chaque sous-étape pourra être vérifiée jusqu’à atteindre un niveau de fiabilité satisfaisant. Par exemple, sur le problème évoqué plus haut de véracité des informations, l’agent pourrait être équipé d’un outil de fact-checking :

Il est aussi nécessaire de garder une bonne méthodologie, voici celle que je vous propose :
Clarifier votre process : avant même d’appeler un agent IA, définissez les objectifs, les sources prioritaires, les formats de sortie (tableaux, slides, etc.).
Structurer l’arborescence : listez les étapes-clés (mots-clés, types de documents, pistes d’investigation). L’objectif : aider l’IA à mieux organiser sa recherche et réduire le risque d’erreur en fonction de vos attentes.
Vérifier et valider : même l’agent le plus performant peut “halluciner” ou mal évaluer la crédibilité d’une source. Conservez un œil critique sur le résultat final, surtout s’il a un impact business ou scientifique.
Itérer et faire des tests : plus vous utiliserez l’agent dans vos process, plus vous allez comprendre ses limites, son fonctionnement, l’impact des instructions, etc
L’un des meilleurs leviers d’efficacité consiste à mieux “instruire” l’IA en amont : ne jamais se satisfaire de la première réponse, reformuler ses questions, fournir des exemples de sources fiables, etc.
Pour finir,
La recherche automatisée est maintenant une réalité opérationnelle. On assiste à un bouleversement majeur dans notre manière de rechercher et de synthétiser l’information, c’est aussi à vous d’exploiter ce changement, tester, adapter les solutions à votre propre réalité.
Les bénéfices sont clairs : gain de temps, réduction des coûts, amélioration du spectre de recherche (accès élargi à de multiples sources).
Il n’y a plus de raison d’attendre… lancez-vous dans l’expérimentation, et voyez jusqu’où cela peut vous mener.
Vous pouvez retrouver cette newsletter où je partage une équipe d’agents IA pour générer un rapport en récupérant des informations sur internet :

🗞️ 3 actus importantes
OpenAI dévoile (encore) un nouveau modèle, un modèle compact mais puissant pour les sciences et le codage
OpenAI a lancé o3-mini, une version optimisée de son modèle de raisonnement o3, intégrée à ChatGPT et disponible via API. C’est un modèle de raisonnement, très bon en mathématiques, sciences et programmation, avec un faible coût et une latence réduite.
La différence ? des réponses 24 % plus rapides, et un taux de préférence utilisateur de 50 % supérieur.
Les utilisateurs peuvent ajuster l’effort de raisonnement (faible, moyen, élevé) pour équilibrer précision et vitesse. Par exemple, il y a une version o3-mini-high.
Pour l’instant, les modèles de raisonnement d’OpenAI ne sont pas multimodaux.
À noter qu’OpenAI a triplé les limites de requêtes pour les abonnés Team et Plus, passant à 150 messages par jour.
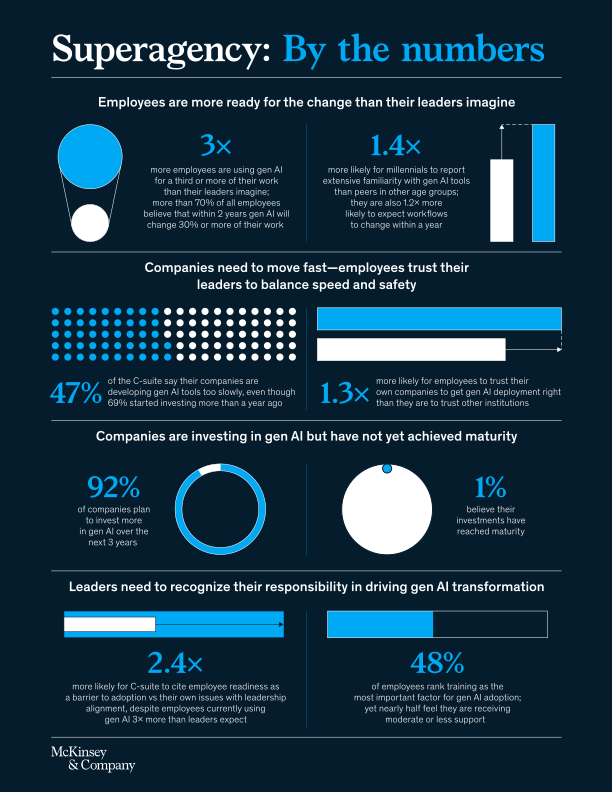
Rapport de McKinsey : “L’IA en entreprise, un potentiel immense, mais des défis à relever”
L’IA promet une transformation aussi profonde que celle engendrée par la révolution industrielle, avec un potentiel estimé à 4,4 billions de dollars en gains de productivité. Pourtant, malgré des investissements croissants, seules 1 % des entreprises déclarent avoir pleinement intégré l’IA dans leurs processus.
Le principal frein ? Le leadership. Selon l’étude de McKinsey, les employés sont bien plus prêts à adopter l’IA que leurs dirigeants ne l’imaginent : ils utilisent déjà ces outils, anticipent l’automatisation de 30 % de leurs tâches et demandent plus de formation. La lenteur des déploiements persiste, souvent à cause de lacunes en compétences ou de processus d’approbation complexes.
Autre défi : la sécurité. Si la rapidité d’adoption est essentielle pour rester compétitif, la confiance des employés repose sur la gestion des risques liés à la cybersécurité, aux biais algorithmiques et à la transparence des systèmes. Malgré ces obstacles, 87 % des dirigeants s’attendent à une croissance de leurs revenus grâce à l’IA dans les trois prochaines années.
Ce qu’il faut retenir : L’IA représente une opportunité historique pour les entreprises, mais atteindre la maturité IA nécessitera des ambitions plus audacieuses et un leadership engagé.
👉 Source
Google accélère sur l’IA avec Gemini 2.0 Pro et Flash Thinking
Google vient aussi de dévoiler plusieurs nouveaux modèles d’IA, dont Gemini 2.0 Pro Experimental et Gemini 2.0 Flash Thinking. Cette annonce intervient alors que la concurrence s’intensifie avec des modèles de raisonnement IA comme DeepSeek R1, qui ont récemment attiré l’attention du marché. J’en parlais la semaine dernière.
Les points clés :
Gemini 2.0 Pro Experimental : Très puissant, toujours une fenêtre de contexte massive de 2 millions de tokens et peut exécuter du code ou utiliser Google Search.
Gemini 2.0 Flash Thinking : ce modèle est conçu pour le raisonnement avancé et la décomposition de tâches complexes.
Ce qu’il faut retenir : Google met à disposition du grand public des modèles IA de plus en plus avancés, réduisant l’écart avec OpenAI et DeepSeek. L’accessibilité et la puissance de ces modèles pourraient accélérer l’adoption des IA génératives à grande échelle.
Merci 🫶🏼
D’avoir lu cette édition jusqu’au bout.
Si ça t’a plu, pense à cliquer sur le ❤️ juste en dessous et partage ton point de vue en commentaire👇🏼
Vous pouvez aussi partager la newsletter à votre entourage (ça me booste beaucoup 🙏) et gagner des cadeaux 🎁
1 parrainage = 1 hack personnalisé
3 parrainages = +400 outils IA triés par thématique et vertical métier
5 parrainages = 30 min de coaching sur votre problématique
À très vite !
Deep research d’OpenAi est il le même que celui dispo dans Perplexity depuis quelques jours? Car en version pro pour 22€/mois, je l’ai trouvé très performant!
Top comme d’hab Louis ! Quality