



Automatiser ses tâches sur chatGPT pour aller plus loin
-> Gagner du temps sans compétence technique
Hello à tous,
Bienvenue dans cette 30ᵉ édition de cette Newsletter !
Tu peux cliquer sur le ❤️ juste au-dessus ou en fin de newsletter si tu apprécies mon contenu. ça m’aide beaucoup ! 🙏
Voici le sommaire de la semaine :
💼 Automatiser des tâches sur GPT
🗞️ 3 actus : Agents IA chez OpenAI, environnement et risque de l’IA
⚡ Démos & outils : Realtime API (encore), retirer les filigranes d’images gratuitement
⏳ Temps de lecture : 10 min
💼 Automatiser des tâches sur GPT
Automatiser des tâches avec l’IA, c’est un peu l’objectif une fois que l’on a cerné la puissance de la techno.
Et c’est encore plus vrai avec chatGPT quand on l’utilise régulièrement.
Mais avant de vous partager des conseils pour automatiser votre utilisation de chatGPT, il est important de ne pas se précipiter.
Automatiser avec raison
L’automatisation prend du temps et a aussi des contraintes :
maintenir le process dans la durée
gérer les erreurs
anticiper les cas particuliers
se plonger dans la documentation (API) ..
etc
Ceux qui s’y sont frottés savent de quoi je parle.
Par exemple, automatiser des tâches occasionnelles qui vont vous prendre quelques minutes à chaque fois, il y a de grande chance que ça ne soit pas utile.
Prioriser vos automatisations avec l’impact possible en temps ou gain financier (réduction de coûts / gain de CA)
Quoi automatiser ?
Parfois, on ne se rend pas vraiment compte de ce que l’on peut faire.
Quelques idées :
Consulter vos historiques de chat sur chatGPT pour identifier les requêtes classiques
Jeter un œil à votre calendrier sur les 3 derniers mois pour identifier les tâches répétitives
Penser à toutes les taches classiques du quotidien (type recherche d’informations pour un produit ; identifier le produit le plus pertinent pour un client en fonction de plusieurs critères; rédiger des présentations; etc)
Sinon, vous pouvez retrouver des idées d’automatisations dans mes précédentes éditions.
Étapes préliminaires avant l’automatisation
Personnellement, je vois trop souvent l’envie d’aller rapidement sur l’automatisation sans avoir testé la précision des modèles IA, et vérifier si les résultats répondent aux standards de l’utilisateur, si la régularité du résultat est au rendez-vous, …
On a facilement l’objectif en vue mais on se perd en chemin.
Pour commencer, créer un GPT reste selon moi le meilleur moyen de savoir si la tâche pourra être réalisé par l’IA (ou en partie).
Rappel : un GPT, c’est une version personnalisée de chatGPT avec vos propres instructions “system” (instuctions par défaut du modèle) + une base de connaissance + la création d’actions.
Une fois crée, vous pouvez utiliser votre propre GPTs facilement
Sur cette étape, il sera sûrement nécessaire d’itérer pour améliorer les résultats. Cette itération se fait au fur et à mesure, car il est difficile d’anticiper le comportement du modèle, difficile de rédiger du 1ᵉʳ coup des instructions complètes qui couvrent tous les cas de figure.
Il y a 2 techniques que vous pouvez utiliser pour améliorer les résultats :
Le prompt engineering
Rappel sur le prompt engineering : l'utilisation de techniques et d’outils pour concevoir et optimiser les prompts (instructions) données à des modèles d'IA, afin d’obtenir des performances maximales et des résultats précis.
Le RAG - Retrieval Augmented Generation (recherche en base de connaissance)
Rappel sur le RAG : une fonction recherche dans une base (vectorielle) documentaire pour trouver des informations pertinentes en lien avec votre demande à partager au modèle en plus de vos instructions → on apporte du contexte.
Ce sont les techniques les plus simples et efficaces (ça tombe bien) pour améliorer vos résultats. Voici un schéma pour résumer ça :

Ici je ne parlerai pas du fine-tuning, une 3ème technique plus avancée mais pas utile dans la majorité des cas.
Un résumé de bonnes pratiques pour les instructions pour un GPT :
Structurer vos instructions en format markdown (titre, liste à puces, etc)
Écrire le couple déclencheur / tâche et découper les étapes si besoin
Ajouter des détails précis sur la base de connaissance (nom du fichier + cas d’utilisations + exemple)
Ajouter des détails précis sur les actions (nom des actions + cas d’utilisations + exemple)
Préciser le format de sortie et des étapes de vérification
Un résumé de bonnes pratiques pour la base de connaissance :
Avoir un formatage simple (= 1 colonne de texte) ou des noms de colonnes explicites s’il y en a plusieurs
Ne pas utiliser le format PDF
Les images ne sont pas pris en compte
La taille totale max des fichiers est 512 Mo et pas plus de 2 millions de tokens
Demander au modèle de partager la source de la base de connaissance dans les instructions (vérifier les informations)
Pendant votre itération, l’idée est d’ajuster ces 2 éléments pour arriver au niveau de précision le plus avancé.
Voici une grille d’évaluation permettant d’ajuster en fonction de l’origine de l’erreur :

À partir de quand la précision est suffisante ?
L’idée est de définir le % de précision nécessaire pour avoir un ROI.
À noter que les tâches de rédaction ne rentrent pas dans cette partie, il n’y a pas de bonnes réponses étant donné que le résultat est subjectif. Sauf si vous avez un cahier des charges suffisament précis.
Qu’est-ce que signifie la précision pour votre cas d'utilisation spécifique ?
Cela peut sembler évident, mais il existe une différence entre produire un mauvais contenu qu'un humain peut corriger et rembourser un client de 500 € au lieu de 50 €.
Il est important de définir la précision du LLM nécessaire avec une idée approximative du coût d’échec du modèle et des économies ou des gains de succès possibles.
Cela permet d’identifier si le niveau de précision est « suffisamment bon » pour la production.
OpenAI partage un tableau intéressant, avec ce type de format :

L’idée est de déterminer l’impact de chaque statut, et de simuler une répartition pour savoir la précision minimum à aller chercher
Dans cet exemple, avec 1% d’échec grave 19% d’échecs amenant une notification à un humain, la précision nécessaire est d’environ 80% pour être à l’équilibre.
Mais tout dépend de votre situation !
Une fois que le point mort est déterminé, cela vous permet ensuite de vous concentrer sur les 10 à 20% non résolues pour limiter l’impact des erreurs :
identifier les cas où il y a une erreur qui impact le business, et laisser à l’assistant la possibilité de ne pas traiter le ticket si c’est sensible
transférer à un humain si l’intention n’est pas clair et/ou demander plus d’informations, reformuler la demande de l’utilisateur
ajouter des étapes supplémentaires (de garde-fous) et découper en amont la tâche avant de mobiliser le modèle. L’idée est d’avoir un délai de réponse plus long par le modèle mais pour améliorer la précision (un peu comme le modèle o1)
Sortir de l’interface
Si vous estimez que votre GPT est suffisament précis, le challenge est maintenant de sortir de l’interface.
Pour cela, vous pouvez facilement basculer sur des assistants API en copiant tout ce que vous avez réalisé sur votre GPT : les instructions, la base de connaissance, …
Vous pouvez même optimiser certains réglages comme :
le traitement de votre base de connaissance

la température, top P (gérer la probabilité des mots) et le format de réponse
Les assistants sont utilisables depuis l’interface playground, mais surtout par API, permettant de l’intégrer dans un process d’automatisation nocode comme avec Zapier ou Make, ou encore dans vos process internes.
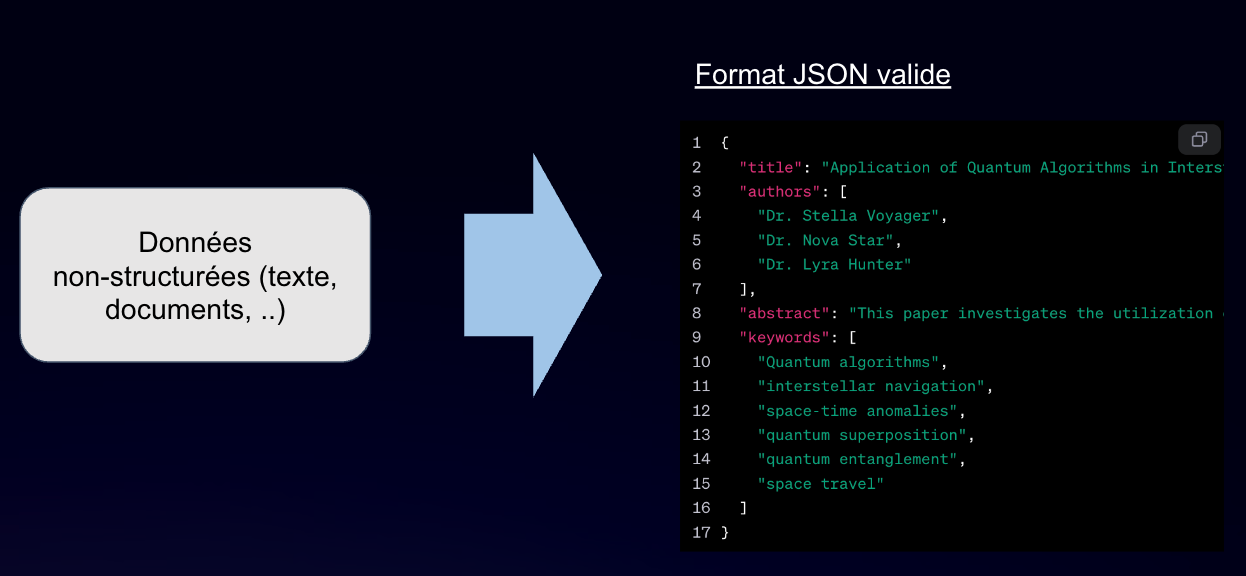
La possibilité de forcer le modèle à respecter un JSON est très intéressant pour permettre la communication avec d’autres outils.
C’est un format facilement gérable par des outils tiers.
Aller plus loin
Je n’ai pas mentionné les actions (function calling sur les assistants) permettant de déclencher des appels API à d’autres outils pour que l’assistant récupère des informations qui vont lui permettre de réaliser des tâches, type :
“ je partage à un assistant un ticket client avec l’adresse mail du client” → il va récupérer les informations du client dans le CRM depuis son mail pour apporter du contexte à sa réponse.
C’est super utile mais ça sera pour une prochaine édition.
En bref,
L’idée était surtout de vous partager le potentiel d’automatisation des modèles IA comme chatGPT, mais surtout ne pas griller les étapes pour y arriver, au risque d’impacter négativement vos process, créer de la frustration, déception.
J’ai listé tous les détails que j’aurais aimé avoir avant de me lancer dans l’automatisation d’un process avec un modèle IA, j’espère que vous avez apprécié le contenu, je vous prépare une surprise pour la semaine prochaine ! :)
N’hésitez pas à soutenir cette newsletter par un like, un partage ou un abonnement si c’est pas le cas :)
🗞️ 3 actus IA
OpenAI partage ses challenges sur les systèmes multi-agents
OpenAI cherche à doter les Assistants API d’une architecture robuste multi-agents pour étendre les possibilités d'utilisation.
Mais il y a un problème majeur : la dégradation de la donnée (ou le téléphone arabe).
OpenAI partage du contenu sur les agents IA sur 3 niveaux :
1️⃣ Swarm : un framework d’orchestration multi-agents
2️⃣ Cas concret : le dernier use case partagé par OpenAI inclut des agents autonomes
3️⃣ Guide pratique sur l’utilisation de réponse structurée dans la gestion de MAS (multi-agents system)
Pour rappel, le principe des systèmes multi-agents est de pouvoir gérer de manière autonome une tâche complexe nécessitant plusieurs actions, grâce à des agents réalisant une tâche spécifique, voir une sous-tâche.
Ce découpage permet d’améliorer la performance globale.
L’idée d’avoir des assistants plus restreints, mais plus performants, permettrait plus facilement de réduire cet écart.
Sans faire des prompts plus complexes ou anticiper tous les use cases, simplement en découpant les tâches.
Et le plus gros challenge actuellement, c’est la dégradation de la donnée au fur et à mesure des échanges entre agents. Un peu comme le téléphone arabe entre agents où on a une perte d’informations au fur et à mesure.

Et si l'IA était l’opportunité pour accélérer l'énergie propre
L'explosion de la demande en électricité des centres de données pour l'entraînement de l'IA pourrait bien être un levier inédit pour accélérer la transition énergétique. Les géants de la tech, pressés de gagner la course à l'IA, investissent massivement dans des sources d'énergie propres comme le solaire, les batteries, et même le nucléaire, malgré les coûts élevés. Microsoft, par exemple, a récemment déboursé 16 milliards de dollars pour prolonger la durée de vie d'une centrale nucléaire. Ces investissements massifs, motivés par des engagements climatiques ambitieux (neutralité carbone d’ici 2030), permettront de faire baisser le coût des technologies énergétiques propres, tout en surmontant des obstacles réglementaires. Bien que l'IA augmentera temporairement les émissions, elle pourrait à terme transformer le secteur énergétique en stimulant une adoption rapide des énergies renouvelables.
👉 Source
L’auteur de “Sapiens” partage son inquiètude sur l’IA : “une entité étrangère prenant le contrôle des systèmes humains de l’intérieur”
Dans une interview, Yuval Noah Harari partage les implications de l’IA qu’il considère non pas comme un simple outil, mais comme un agent autonome, voire un "intelligence étrangère".
Selon lui, l’IA présente un risque unique, car elle agit à l’intérieur des systèmes humains existants, prenant des décisions autonomes dans les domaines clés de la finance, de l’éducation et des armées. Il met en garde contre les dangers que cela représente, y compris la manipulation des dirigeants politiques, et souligne l’urgence de construire des mécanismes de régulation efficaces pour éviter de graves erreurs dans les décennies à venir.
Cela fait écho au passage de Yann le Cun en Suisse, qui avertit sur l’opacité et la puissance de quelques grandes entreprises
👉 Source : Noema Magazine
⚡ Démos & Outils
Realtime API
La semaine dernière, je vous partageais des exemples d’utilisations de l’API vocal d’OpenAI. En voici d’autres, je trouve ces démos très intéressantes sur le futur du vocal dans les produits que l’on peut utiliser, y compris dans les process interne des entreprises.
Pourquoi son mode vocal est si puissant ?
latence remarquablement faible, d'environ 500ms, soit deux fois plus rapide que ce qui est disponible sur le marché
synthèse vocale nettement améliorée.
OpenAI a réussi à simplifier la création d’agents vocaux en n'utilisant qu'une seule API pour gérer la reconnaissance vocale, la génération de texte, et la conversion texte-voix, alors que 3 outils étaient auparavant nécessaire.
C'est un gain considérable même si, des marges de progression existent encore, notamment en termes de coût (!!) et d'émotion dans les voix générées.
Des agents IA de support client avec Decagon
Decagon : Avec une levée de fonds de 65 millions de dollars lors de son tour de table Series B, mené par Bain Capital Ventures, Decagon continue de révolutionner le support client grâce à ses agents IA. En collaboration avec des entreprises comme Duolingo et Notion, Decagon permet d'automatiser 70% des interactions clients, réduisant drastiquement les coûts tout en améliorant l'efficacité. Son IA s'adapte aux besoins spécifiques des grandes entreprises, offrant une solution capable d'évoluer et d'apprendre de chaque conversation. Un gain de temps pour les équipes support, qui peuvent désormais se concentrer sur des tâches à plus forte valeur ajoutée.

Retirer des filigranes sur une image
Watermark Remover : outil en ligne gratuit pour supprimer rapidement et efficacement les filigranes des images, une fonctionnalité précieuse si vous travaillez régulièrement avec des contenus visuels. L’outil vous aide à obtenir des images propres sans perte de qualité et propose également des options d'intégration API pour automatiser ce processus à grande échelle, accélérant ainsi vos flux de travail et améliorant la productivité.

Merci 🫶🏼
D’avoir lu cette édition jusqu’au bout.
Si ça t’a plu, pense à cliquer sur le ❤️ juste en dessous et partage ton point de vue en commentaire👇🏼
Vous pouvez aussi partager la newsletter à votre entourage (ça me booste beaucoup 🙏) et gagner des cadeaux 🎁
1 parrainage = 1 hack personnalisé
3 parrainages = +400 outils IA triés par thématique et vertical métier
5 parrainages = 30 min de coaching sur votre problématique
À très vite !