



#5 | Créer son propre GPT : intégrer vos connaissances dans un LLM

Hello à tous, bienvenue sur cette 5ᵉ édition ! 🎉
Sur la précédente édition, j’avais utilisé un outil pour injecter des données au LLM afin qu’il rédige un brouillon personnalisé.
Je reviens sur cette notion pour vous permettre de créer votre propre GPT avec une interface partageable à tous.
Sommaire
Case Study : Tutoriel pour créer pour son propre GPT
Introduction : l’embedding knowledge base
Création de notre base de connaissance
Création de l’outil (+chat)
Résultat et bilan
Top news IA
Outils IA type Knowledge Base
Retour d’expérience
Case Study : Créer son propre GPT avec l’embedding de base de connaissance
L’objectif de l’édition : créer une interface permettant de poser n’importe quelle question très technique sur un sujet précis (l’investissement immobilier dans l’exemple) pour avoir une réponse ultra complète.
Pour créer votre propre GPT boostée par vos données, on va utiliser la technique de l’embedding knowledge base.
Pour rappel, une base de connaissance permet aux équipes de trouver facilement une information sur un sujet donné. Dans notre exemple, je prends l’exemple d’une entreprise qui propose énormément de produits (plus d’une cinquantaine), très difficile de tous les connaitre, surtout quand ces derniers sont amenés à évoluer.
Pourtant, on a parfois des questions précises sur certains produits. C’est particulièrement difficile pour de nouveaux arrivés d’avoir les connaissances suffisantes sur ces produits, tout en apportant une réponse au client.
Tout serait largement simplifié avec un GPT incluant votre base de connaissance spécialisée sur les produits de l’entreprise.
Pour rendre l’IA plus intelligente sur votre demande, on utilise le knowledge base embedding.
Explication du knowledge base embedding
Les IA sont entrainées sur une grande quantité de textes, toutes ces connaissances sont implicites et non structurées. Si on demandait à ces modèles la capitale de la France, le modèle devrait faire une succession de recherches pour déterminer que la réponse est Paris.
Les modèles ont donc intégré des bases de connaissances, c’est comme des "encyclopédies" informatiques, où chaque information est stockée de manière structurée et reliée. C’est le cas de site comme Wikidata, la base relie “Paris” aux informations “capitale de la France” + toutes les caractéristiques liées à Paris.
Le knowledge base embedding consiste à intégrer ces informations structurées dans les représentations apprises par l'IA. Et la bonne nouvelle, c’est qu’on peut nous aussi lui apporter de la donnée structurée.
Le knowledge base embedding est un mix entre :
un vaste jeux de données non structurées
l’ajout de connaissances structurées et reliées (les informations produits dans notre cas)
C'est l'une des clés pour créer des IA plus fiables, capables de raisonnements complexes et de dialogues naturels. Cette techniques de knowledge base embedding révolutionnent la recherche d'information !
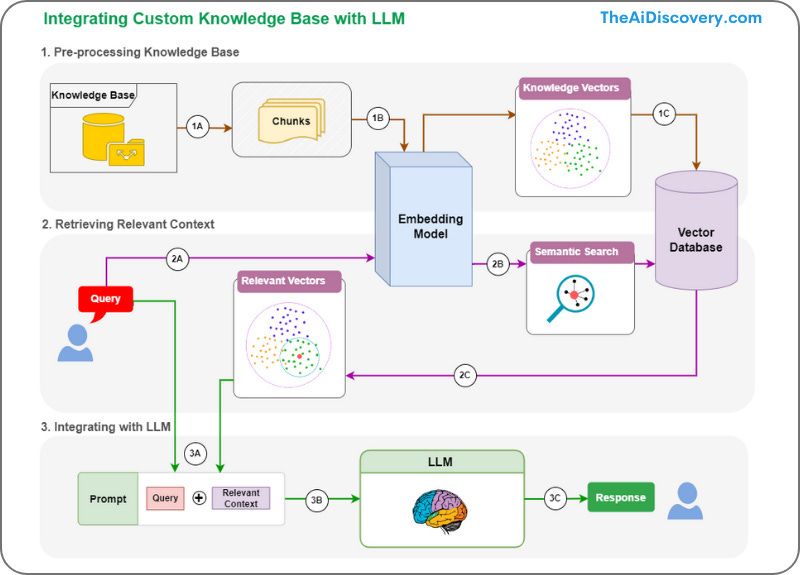
Petit schéma qui résume cette approche en 3 phases :
le traitement de la base de connaissances pour l’injecter dans l’embedding model qui va intégrer cette donnée dans une base de données vectorielles
l’utilisateur fait sa demande qui va passer à travers une recherche sémantique sur les informations structurées (base de données vectorielles) pour ajouter du contexte au prompt.
L’ensemble de la demande est envoyé au LLM pour fournir la réponse à l’utilisateur
La création de notre base de connaissance
Pour créer notre base de connaissance à injecter, il nous faut structurer la donnée. J’ai sous la main une base de données qui concentre une grande information sur des produits financiers en accès libre. (plus de 70 produits)
Je vais pouvoir construire un CSV avec toutes ces données et l’ajouter dans la partie data d’un outil comme [Relevance.ai]. Grâce à cet outil, je vais pouvoir transformer mon CSV en une base de données vectorielles et qui sera injecté ensuite dans le LLM.
Pour rappel, la base de données vectorielles permet de stocker et rechercher des données basées sur leur similarité. C’est de cette manière que l’IA réussit à trouver des informations pertinentes en lien avec la demande utilisateur.
C’est un peu comme si chaque information de notre base de données est convertie en un code-barres unique. Le principe de la vectorisation transforme chaque donnée en un vecteur, une sorte d'empreinte numérique. Tous ces vecteurs sont ensuite rangés dans une grande bibliothèque, la fameuse base de données vectorielles. Quand on lance une requête, l'IA scanne tous les code-barres pour dénicher en un éclair ceux qui ressemblent le plus à notre demande. Elle renvoie les informations correspondantes de manière ultra pertinente.
Exemple du processus de vectorisation qui va ensuite stocker la donnée dans une base de données vectorielle structurée :

Bref, en gros ce travail n’est pas à faire avec un outil comme Relevance.ai et ça nous arrange bien !
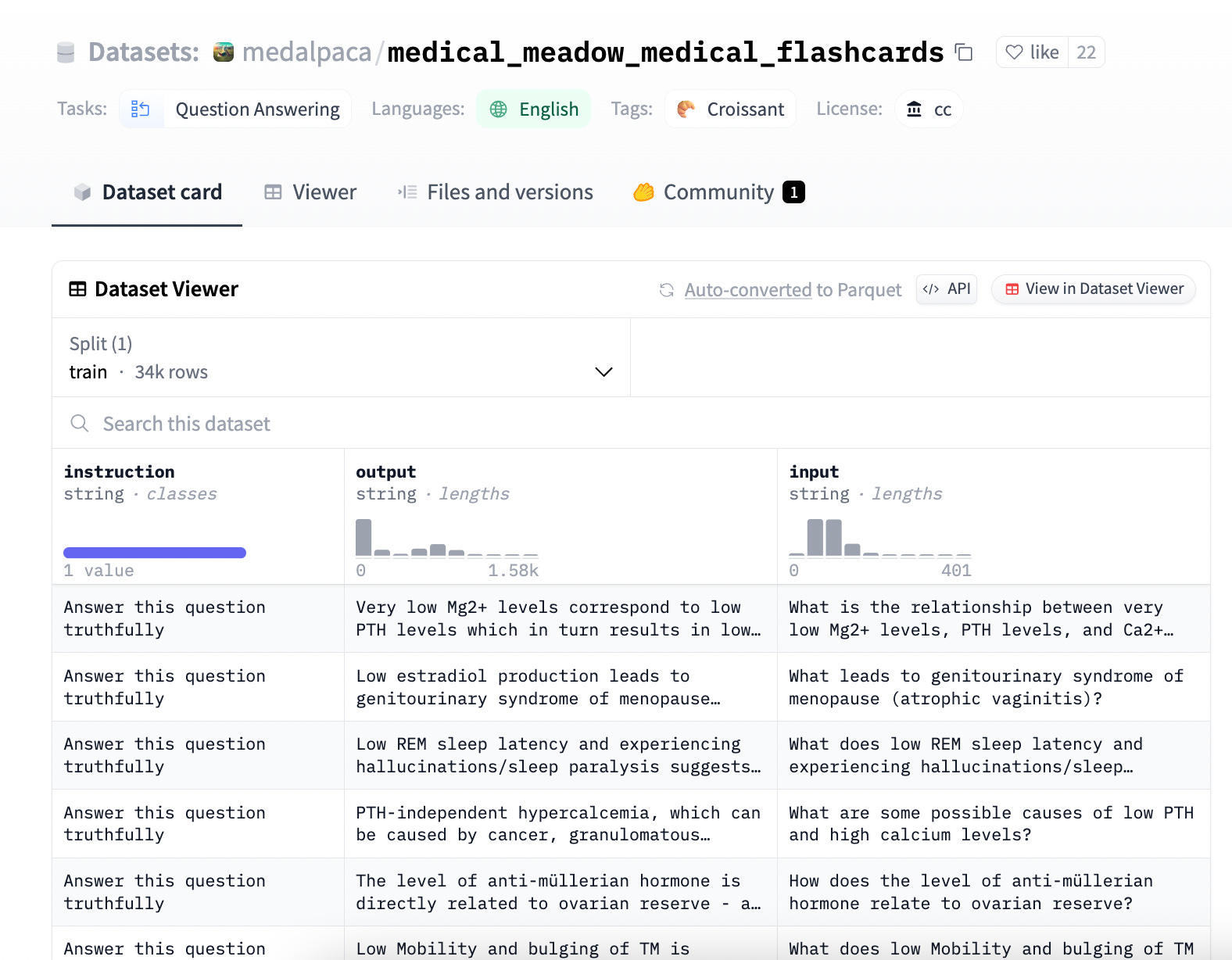
Si vous voulez faire des tests et créer votre propre base de connaissance, vous pouvez retrouver des datasets sur Kaggle ou Hugging-face sur des sujets très pointus.
Un exemple de datasets de 34 000 lignes sur des fiches couvrant l'intégralité du cursus de médicines (avec des sujets comme l'anatomie, la physiologie, la pathologie, la pharmacologie, ..)
Création de notre outil de réponse aux questions produits
Une fois la base de connaissance prête, on va pouvoir l’exploiter dans une interface.
On a ajouté les connaissances produits en base sur Relevance.ai.

On crée un prompt en lien avec notre besoin et l’outil lui injecte les données les plus pertinentes par rapport à la question (input de l’utilisateur).

Au final, le process ressemble à ces étapes :
Avec la particularité qu’une partie de notre base d’informations est partagée aux modèles pour compléter sa réponse.

Résultat
Voici une démo de l’interface :
Je demande une explication sur un produit financier présent dans la base et j’ai directement les informations pertinentes sur le produit.
Un vrai gain de temps pour un conseiller financier par exemple !
Pour vous montrer la différence du résultat, voici le résultat que l’on obtient sur une demande

L’outil que vous avez crée est accessible depuis un lien partageable sans aucune connexion, vous pouvez le partager avec votre équipe.
Bilan
Le succès d’un tel projet réside dans la qualité des données (comme c’est souvent le cas en IA). Il est important de s’assurer que les données sont fiables, complètes et bien formatées. Cela demande du temps.
La plupart des connaissances sont souvent stockées dans la tête des opérateurs / commerciaux / .. et même quand c’est mis par écrit, le format change entre des Google Docs, notions, captures d’écrans, … et personne ne sait si la donnée est à jour !
Le knowledge base embedding reste un formidable exemple d’utilisation de l’IA, facilement implémentable pour une entreprise pour exploiter ses propres données. Cette technique permet d’enrichir un modèle avec des connaissances explicites.
Les réponses sont plus précises en apportant des données plus personnalisées sur des marchés spécifiques. Cela améliore drastiquement l’efficacité des équipes et la rapidité d’accès à l’information.
D’autres exemples concrets d’utilisations de la knowledge base embedding :
Côté juridique, il serait possible de retrouver tous les jugements en lien avec un cas précis, même sans connaître le jargon juridique exact, avec une base de connaissances des textes de loi, jurisprudences et contrats.
Côté immobilier, en intégrant les annonces, les photos, les plans, les diagnostics... Les acheteurs ou conseillers immobiliers pourraient récupérer l’ensembles des annonces correspondant à des critères précis : "maison avec jardin proche écoles avec un DPE supérieur à F situé à moins de 5 min du métro”.
Côté santé, la techno appliquée aux dossiers médicaux faciliterait le diagnostic en trouvant rapidement les cas similaires et les traitements associés.
Côté assurance, cela pourrait enrichir une base de connaissances avec les contrats, clauses, constats, déclarations de sinistre pour répondre instantanément aux demandes de renseignements (internes ou clients).
Côté RH, avec une base unifiée sur les descriptifs de postes, les CV et les évaluations, il serait possible de sortir les meilleurs CV reçus.
Top news IA ☕
Au sommaire des actualités de la semaine :
Un rapport de Standford sur l’IA
La technique de Google pour gérer un contenu très large
Adobe et la génération de vidéo
Stable Diffusion disponible par API
Les retours de performance du nouveau modèle Mistral
Des outils IA ⚒️
Le premier outil est justement un outil de knowledge base et français 🇫🇷.
Dust - Votre GPT personnalisée (la démo clé en main)
Dust est un outil de productivité alimenté par l'IA, qui fournit des réponses adaptées au contexte, en exploitant les sources de connaissances internes à l’entreprise. L’objectif est de rendre l’accès à l’information interne accessible à tous. L’outil vous accompagne dans vos demandes précises sur des clients, process internes, les produits de l’entreprise, etc.
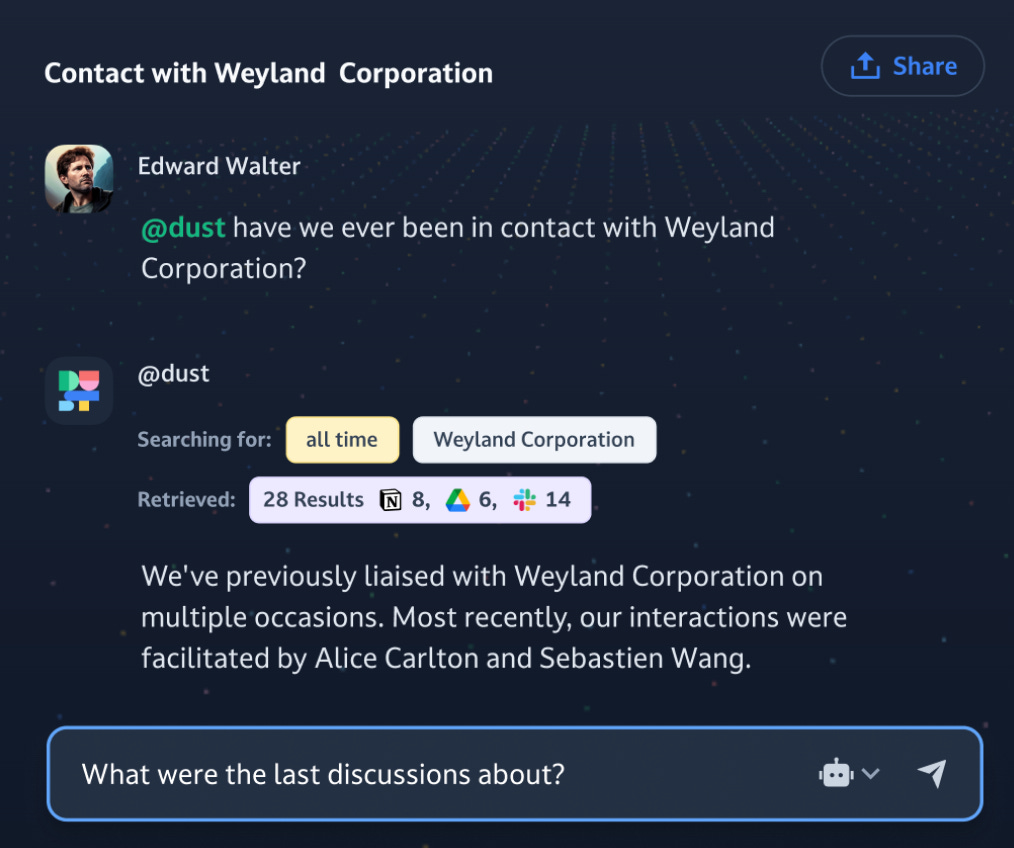
Concrètement, vous autorisez Dust à accéder à vos outils de stockage d’informations (Drive, Notion, Slack, Github, Salesforce) et vous pouvez faire n’importe quelle demande via le modèle de votre choix (GPT, Claude, Mistral, …)
Flipner
Flipner vous aide à créer du contenu et est un vrai assistant personnel pour la rédaction. Par exemple, vous pouvez lui envoyer des vocaux et il se chargera de rédiger un contenu structuré en format long. Une occasion de structurer vos pensées sans prise de tête.
L’IA est souvent très utile pour la mise en forme d’un contenu. Avec cet outil, plus besoin de se prendre la tête sur la forme, vous lui envoyez du contenu non structurée et sous différents formats (audio ou texte), il se charge de la structuration.
En moyenne, on est 5 fois plus lent pour écrire du contenu que le dire oralement. Le gain de temps peut être énorme.

Vous pouvez personnaliser le style d’écriture et faire des modifications post-rédaction.
L’outil a un plan gratuit si vous souhaitez le tester.
Retour d’expérience 👣
Bonne nouvelle, la semaine dernière, un projet IA sur lequel je travaillais est maintenant en production ! J’en parlerai prochainement sur LinkedIn mais cela fait tellement plaisir de voir la valeur créée avec l’IA et en plus directement aux utilisateurs de la solution.
J’ai aussi eu l’occasion d’échanger avec plusieurs entreprises pour implémenter l’IA dans leur process et c’est flagrant de voir le niveau d’avancée sur le sujet et la vision qu’ils ont. J’ai identifié 3 catégories :
l’entreprise a un besoin précis et souhaite trouver une solution avec l’IA. En général, le décisionnaire sait qu’il est possible de résoudre cette problématique avec l’IA. Le process est identifié, ça va vite, la deadline est presque fixée.
l’entreprise voit la tendance de l’IA, elle est outillée mais n’a pas le temps de se pencher dessus. Elle a besoin d’un accompagnement pour défricher les process qui peuvent être automatisés. Il y a une volonté d’implémentation mais une priorisation à définir. On va y aller progressivement
l’entreprise se sent déjà dépassée par l’IA, elle est très peu outillée mais espère court-circuiter sa “transformation digitale” en boostant certains process avec l’IA. Elle ne sait pas comment s’y prendre, elle n’est pas à l’aise avec le sujet, les décisionnaires ne sont pas volontaires. C’est déjà trop tard ?
C’est terminé pour la 5ème édition ! Je suis toujours preneur de vos retours, notamment si vous souhaitez que je présente certains cas concrets qui répondent à vos problématiques.
N’hésitez pas également à soutenir la newsletter si vous appréciez le contenu : likes, commentaires, partages …
À très vite 💪