

#3 | Génération d'images : guide, outils et démo 🖼️

Hello à tous, bienvenue sur cette 3ᵉ édition ! 🎉
Vous connaissez Thispersondoesntexist.com ? Un générateur d’image qui crée le visage d’une personne qui n’existe pas. On creuse ce sujet dans cette newsletter.
Sommaire
Introduction
Case Study : Génération d’images avec l’IA
Comment ça fonctionne ?
Les outils et comparaison
Création d’un prompt pour image
Application en Ecommerce
Conseils et limites
Bilan
Top news IA
Quickwin sur les Outils IA
Retour d’expérience
Case Study : génération d’images
La génération d'images par l'IA a connu des progrès fulgurants ces dernières années. On est passé en quelques années de résultats flous et peu convaincants à des images bluffantes de réalisme, grâce à l'essor de nouvelles architectures de réseaux de neurones comme les GAN (Generative Adversarial Networks) et à la disponibilité de gigantesques jeux de données d'images pour entraîner les modèles.
Un aperçu du progrès de DALL-E aux derniers outils :


Comment ça fonctionne ? 🤔
Les modèles sont capables de générer des images venant d’un prompt ou d’une autre image :

Maintenant, on creuse comment le modèle fonctionne grossièrement : (⚠️ il y a de nombreuses variantes techniques derrière chacune des étapes, c’est un aperçu)
L’IA doit comprendre la demande textuelle. Elle fait une analyse de texte grâce à son module NLP (traitement de langage). Elle convertit la demande en une représentation numérique qu’elle pourra traiter. La représentation numérique obtenue capture le sens de la phrase, un peu comme un vecteur de mots-clés.
Elle commence à faire une première version, en très basse résolution (imaginez un croquis flou et pixelisé). On parle alors souvent de génération d’un “bruit”. Le bruit généré est aléatoire, c'est-à-dire un ensemble de pixels sans structure particulière. Cette image de bruit est de petite taille, par exemple 64x64 pixels.
Le modèle commence alors un débruitage progressif de l'image qui se déroule en plusieurs étapes appelées "timesteps". La stratégie de débruitage est déterminée par le "scheduling", qui définit la fonction mathématique la plus pertinente pour contrôler l'évolution du débruitage au fil des timesteps, c’est-à-dire l’évolution pour améliorer la qualité visuelle de l’image.
L'objectif est d'obtenir l'image finale en un minimum de timesteps, tout en étant cohérent avec la demande initiale.
À chaque timestep, le débruitage est effectué par une architecture de réseau de neurones appelée "U-net". Cette architecture est composée de deux parties :
La partie "encodeur" (la descente du U) qui compresse progressivement l'image en capturant ses caractéristiques essentielles.
La partie "décodeur" (la remontée du U) qui reconstruit progressivement une image haute résolution à partir de ces caractéristiques.
À chaque timestep, le U-net retire un peu de bruit, permettant d'obtenir des images plus nettes, plus détaillées et plus esthétiques au fil du processus itératif de création d'image.
On obtient ainsi une image finale en haute définition, fidèle à la description textuelle initiale.
Voici un petit schéma reprenant les différentes étapes :

Une autre technique particulièrement pertinente lors de la création d’images réaliste consiste à un réseau de neurones antagoniste où deux sous-réseaux vont s’affronter : le générateur et le discriminateur. C’est appelé un GAN (Generative Adversarial Network).
Le générateur, qui apprend à créer de fausses images ressemblant aux vraies
Le discriminateur, qui apprend à différencier les vraies images des fausses en utilisant sa base de données

Comme vous pouvez le voir, les techniques sont différentes en fonction de la demande initiale.
Sans s’attarder sur les techniques de création d’images, le fonctionnement de l’IA est en réalité assez proche d’un dessinateur. Une fois les consignes comprises, l’ébauche rapide permet de poser les bases de composition (à la manière d’un croquis) pour ensuite ajouter / enlever progressivement des détails, colorations, corrections, …
La grande force de l’IA n’est pas seulement dans sa capacité à générer une image rapidement et automatiquement, mais aussi de pouvoir produire des images en grande quantité. Cette variation d’image permet de repousser les limites de la créativité en apportant de nouveaux éléments.
Pour aller plus loin, voici une vidéo explicative sur le fonctionnement des IA.
Outils et comparaison
Il existe de nombreux outils de génération d’images. Pour citer les plus connus, on retrouve :
Dall-E d’Open AI : simplicité d’utilisation car directement depuis chatGPT. Comprend bien la demande textuelle. 20$/mois avec GPT-4.
Midjourney : un des outils les plus puissants pour la génération d’image mais utilisation depuis discord, 10$/mois pour environ 200 images/mois.
Stable Diffusion : parfait pour la personnalisation et un meilleur contrôle des images. La solution est open-source, à partir de 10$ pour 1 000 credits.
Adobe FireFly : utile pour ajouter du contenu sur des photos et intégrer à Photoshop, à partir de 20$/mois.
Leonardo.ai : réunit plusieurs modèles et fournit une interface simple d’utilisation. L’un des meilleurs outils actuellement sur le marché. Gratuit pour quelques images, sinon à partir de 10$/mois.
Des alternatives 100% gratuites existent comme AIImageGenerator.tools.
En fonction de votre usage, certains outils sont plus adaptés que d’autres.L’outil que j’ai principalement creuser est Leonardo.ai, car il permet de :
avoir accès à plusieurs modèles IA dont des modèles fine-tuned sur des sujets précis (dont Stable Diffusion)
Propose des options avancées pour affiner les résultats (styles, composition, couleurs, dimensions, ….)
Créer son propre modèle en uploadant des photos
Pouvoir faire des modifications sur des images générées (modification ciblée, upscale pour augmenter la résolution, ..)
Interface conviviale et intuitive, même s’il y a des boutons un peu partout.
Création / modification d’image directement sur canvas.
Création du prompt ✍️
Comme vous le savez, le résultat dépend de votre prompt. Mais les techniques de prompting sur des modèles IA classiques (GPT, Claude, Gemini, ..) sont différentes du prompting pour les images.
Voici des conseils pour un prompting de qualité en image :
Décrire le sujet principal : Commencez par décrire clairement le sujet ou l'élément central de l'image que vous souhaitez générer. Soyez précis sur ce qui doit être représenté.
Spécifier le style ou le genre : Indiquez le style artistique, le genre ou l'ambiance souhaitée. Par exemple : "photo réaliste", "dessin animé", "peinture à l'huile", "noir et blanc", "futuriste", "steampunk", etc.
Ajouter des détails visuels : les détails importants de la scène, tels que le cadrage (gros plan, plan large...), l'angle de vue, l'arrière-plan, les couleurs dominantes, la lumière, les textures, … Ou utiliser des termes techniques comme "octane render" pour un rendu 3D photoréaliste, "bokeh" pour un arrière-plan flou, "film grain" pour un effet de grain, etc
Préciser les émotions ou l'atmosphère : Décrivez l'émotion ou l'atmosphère que l'image doit dégager, comme "mystérieux", "joyeux", "mélancolique", "épique", etc.
Décrire des relations spatiales en précisant la position relative des éléments dans la scène. Par exemple : "un vase de fleurs sur une table en bois devant une fenêtre, avec des rideaux blancs flottant dans la brise".
Bonus :
Jouer avec les négations (negative-prompt) pour exclure certains éléments en utilisant des mots comme "no", "not", "without". Par exemple : "un paysage de montagne, sans buildings, sans humain".
Utiliser des références artistiques : Mentionner le nom d'artistes, de photographes, de réalisateurs dont le style se rapproche de ce que vous recherchez → le modèle utilise sa base données pour générer une image dans le style que vous désirez. Cette étape lui permet de s’inspirer d’un grand nombre de contenu réalisé par l’artiste en question.
Utiliser des échelles et des unités : il est possible de spécifier la taille ou les dimensions des éléments. Par exemple : "une pizza géante de 2 mètres de diamètre, avec des buildings miniatures comme garnitures".
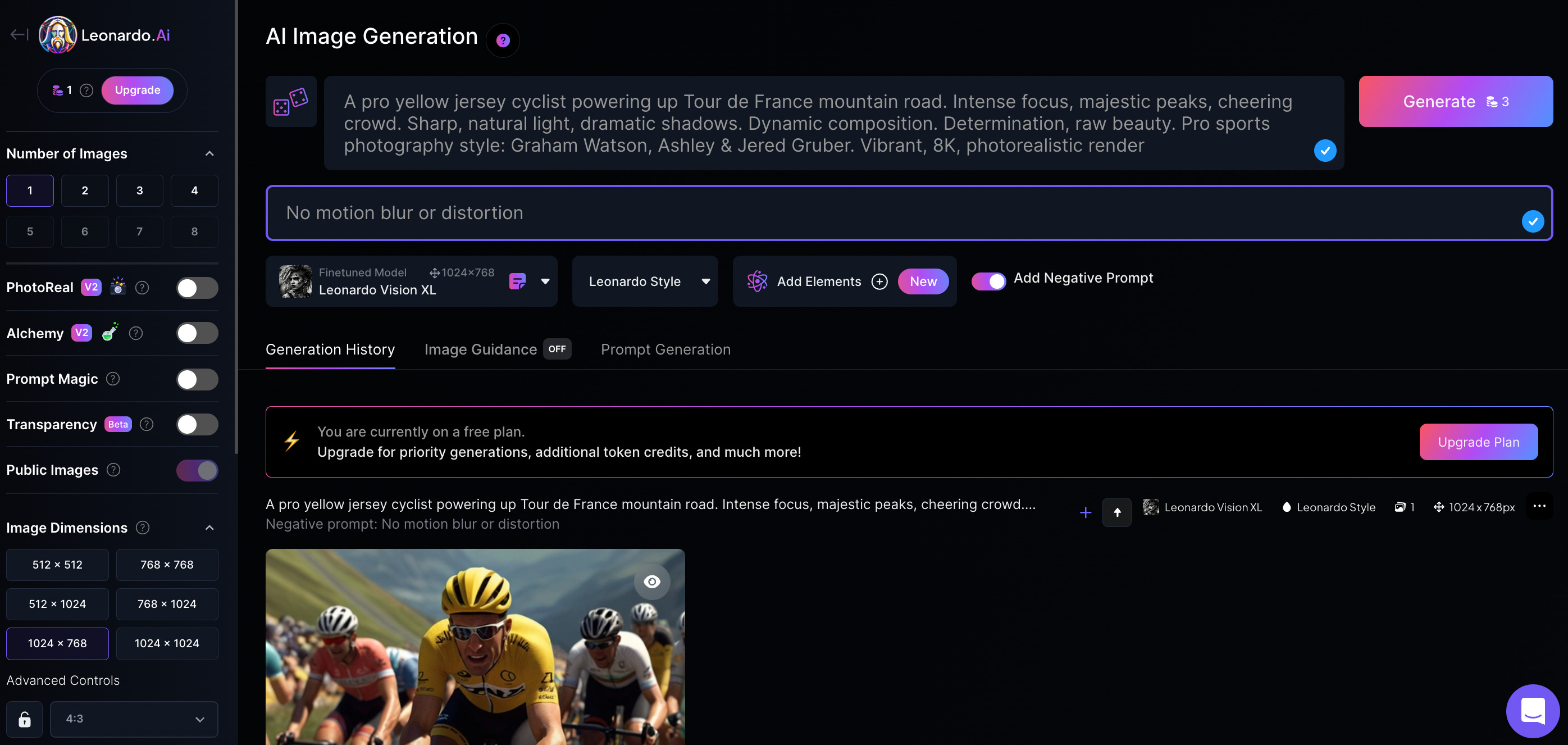
Voici un exemple de résultat utilisant ces techniques (Leonardo s’utilise en anglais)
A pro yellow jersey cyclist powering up Tour de France mountain road. Intense focus, cheering crowd. Sharp, natural light, dramatic shadows. Dynamic composition. Determination, raw beauty. Pro sports photography style: Graham Watson, Ashley & Jered Gruber. Vibrant, 8K, photorealistic render.

L’outil n’utilise pas l’ensemble des éléments du prompt (ou légèrement) et des détails sur les mains du guidon ou la position d’autres cyclistes n’est pas vraiment correct. Comme sur les modèles pour la création d’image, il est parfois nécessaire de venir retravailler précisément certains éléments de l’image.
Pour améliorer les images générés, certains utilisateurs utilisent :
des LoRas ciblés (LoRA pour Low-Rank Adaptation permet d'améliorer des tâches spécifiques de génération d'images) - dans l’image précédente, cela pourrait être sur la génération de mains sur un guidon. Des LoRA "badquality" sont parfois utiliser pour imiter le rendu de mauvaise qualité des photos prises avec un smartphone.
des techniques d'upscaling (x1,5) et de post-traitement
Au début, il n’est pas simple d’être aussi précis et de penser à tous les points. Pour cela, vous pouvez utiliser un outil comme G-prompter qui vous guide dans la génération de prompts de qualité, ou demander à GPT-4 / Claude-3 de générer des prompts pour vous.
Cas concret : Créer des images à la volée pour des pages produits E-commerce
L’ecommerce a un gros besoin de contenu photos pour les produits vendus. Un utilisateur qui consulte des fiches produits sur une plateforme va être très sensible aux images proposées.
Si les images proposées offrent différents points de vue, différentes mises en situation, cela permet de valider l’acte d’achat. Derrière, le taux de conversion est directement impacté.
Pour économiser les coûts liés à des sessions shootings, des modèles très personnalisables comme Stable Diffusion sont super utiles. Il est possible de générer des variations produits sur une image.
Voici un exemple :
Lors de la génération d’image, on peut venir retravailler certains éléments (les mains ici) :

Ce qui est intéressant ici, c’est que l’on part d’une image existante (un modèle) pour appliquer une série de modification. Cela nécessite d’utiliser des extensions spécifiques comme l’Openpose de ControlNet qui permet de conserver la posture du modèle. L’optimisation est aussi permise par d’autres paramètres de remplissage spécifique comme EpicRealism, Realistic Vision ou Clarity, spécialement entrainés pour générer des résultats précis et réalistes.
Un autre exemple :

Sur la dernière photo, on pourrait passer à une phase d’optimisation et ajustement sur la main par exemple.
Un projet existe sur Hugging-Face : Outfit Anyone.
D’autres cas d’usages sont possibles dans l’industrie du divertissement (cinéma, jeux-vidéos, bande dessiné, …) avec notamment la création d'environnements et de personnages réalistes, voir cet article sur l’animation en 2D.
Mais aussi l’imagerie médicale où il est possible d’améliorer la qualité des images de diagnostic (tissus, organes) pour des diagnostics plus précis.
Les limites ❌
Les modèles actuels présentent encore quelques limites, même en retravaillant les images post-création :
Respect approximatif des lois de la physique, de la cohérence sémantique et spatiale → difficulté pour les modèles à faire des détails, par exemple sur les mains sur un guidon dans l’exemple plus haut.
Difficulté à compter et générer un nombre précis d'objets
Tendance à incorporer certains biais présents dans les données d'entraînement (biais de genre, ethniques...)
Difficulté à ajouter du texte correctement (plus simple de le faire sur l’image générée)
Risque que les images générées ressemblent par inadvertance à du contenu protégé existant avec une zone grise sur la propriété et les droits des images créées par IA
Malgré certaines barrières, possibilité de créer des deepfakes → les plateformes réfléchissent à ajouter des mentions quand l’image est généré par l’IA
Bilan
La génération d'images par IA est désormais une réalité grâce aux récentes avancées des réseaux de neurones génératifs. On peut créer des visuels bluffants à partir de simples descriptions textuelles.
Malgré des limites persistantes, les outils ouvrent de nombreuses perspectives créatives (création de bibliothèque inspirative) et sont d’une précieuse aide.
Je n’ai pas eu l’occasion de creuser les outils pour des créations marketing / support de communication malheureusement (comment créer une identité visuelle par exemple). En fonction de votre intérêt sur le sujet, je pourrais faire une 2ème partie.
Top News IA ☕
Cette semaine, je continue le format vidéo condensé 5 min.
Au sommaire :
Projet Stargate : Open AI x Microsoft
Cloner sa voix : technologie et cas d’usage
Créer des sons avec Stable Audio 2.0
Update sur la génération d’images avec DALL-E
N’hésitez pas à partager votre retour pour savoir si vous préférez ce format vidéo ou un format écrit.
Outils IA sur la génération d’images ⚒️
Cette semaine je vous présente des outils en lien avec la génération d’image pour montrer d’autres usages possibles.
La création d’image réaliste
Plusieurs outils se sont spécialisés dans la création d’image ultra-réaliste pour de la création de contenu dans le tourisme, la mode ou même un usage plus personnel de création de photos portrait.
Plusieurs entreprises sont sur le sujet comme Artisse et Photo AI.

Vous pouvez aussi créer des images ultra-réalistes avec Stable Diffusion et des extensions en local.
Un intérieur design pour de la location immobilière
Le fondateur de Photo AI, Pieter Levels, a aussi crée une solution de modification d’image existante pour y ajouter un ameublement design avec Interior AI.
Les photos d’une annonce immobilière pour de la vente ou de la location ont une importance cruciale dans l’intérêt que l’on porte au bien immobilier. L’outil est devenu un carton.

Ce type d’outil va devenir un incontournable pour de nombreuses agences immobilières.

Retour d’expérience 👣
Le sujet de la génération d’image est un gros morceau. En me lançant sur le sujet, je souhaitais vous partager les informations pertinentes et cas d’usages, mais je me suis aussi vite retrouvé noyer dans la masse d’informations.
J’ai trouvé assez peu de use cases business en production. La plupart des partages sont faits par des entreprises baignant dans le secteur (studio de graphisme par exemple pour du divertissement).
Les outils demandent encore une grosse personnalisation et optimisation de résultat pour être sur un rendu exploitable.
La génération d’images pourrait beaucoup apporter aux départements marketing / communication, mais je n’ai pas trouvé de ressources facilement accessible. Peut-être parce que le temps à passer pour obtenir de bons résultats sur l’outil est encore trop important par rapport à l’impact business.
La priorisation des projets IA reste un sujet central.
Quand on regarde une matrice basique entre faisabilité et impact business, les sujets marketing / communication ne sont pas prioritaires et seraient plus de l’optimisation.

L’impact business n’est pas si important (sauf cas particulier), on vient chercher plus de l’optimisation. Une simulation basique des coûts économisés ne serait pas très bonne, en comparaison à d’autres projets.
Cette newsletter était particulièrement gourmande en termes de temps (3 jours entiers). J’espère qu’elle vous permet d’y voir plus clair sur le sujet.
Preneur de retour et n’hésitez pas soutenir la newsletter si vous appréciez le contenu : likes, commentaires, partages …
À très vite 💪