

#1 | Analyse de documents et extraction de données : tests et limites 🤯

Hello à tous, bienvenue sur cette 1ère édition ! 🎉
Sommaire
Introduction
Case Study : Analyse de documents
Cas simple depuis l’interface
Cas avancé avec API
Conseils et limites
Bilan
Top 3 news IA
L’outil IA pour de la documentation interne
Introduction 👋
Ce passage apporte un peu de mise en contexte sur le lancement de cette newsletter. Pour vous rendre directement sur les sujets IA, vous pouvez sauter cette partie.
Depuis mon début en startup il y a 9 ans, j’ai été rapidement attiré par la structuration de process (sûrement par le fait que j’arrivais en 1st employee et que tout était à faire) et automatiser ou optimiser chaque étape. J’ai donc été amené rapidement à utiliser des outils d’automatisation type IFTTT (à l’ancienne), Zapier, Phantombuster, Make, Google Apps Script et j’en passe … sur des métiers sales, marketing et opérations.
À l’époque, on parlait beaucoup d’automatisation chez TheFamily, et on cherchait tous à automatiser le plus possible de tâches. On cherchait à faire des hacks.
Le développement des plateformes de workflow automation comme Zapier permettait de faire de plus en plus de choses. On se confrontait quand même aux limites des fonctionnalités et intégrations de ces plateformes.
Depuis la sortie de chatGPT en novembre 2022, l’univers des possibles sur l’automatisation a explosé. Principalement parce que des tâches basiques comme la rédaction d’un texte, la traduction, l’analyse de données, … sont maintenant possibles avec ces outils.
Cet univers des possibles permet d’aller au-delà des outils existants - qui intègrent d’ailleurs de plus en plus l’IA dans leur propre fonctionnalité (Hubspot, Notion, Aircall, …) - pour aller chercher plus de personnalisation et toucher des process d’automatisation parfois cœur de métier.
Cette opportunité, j’ai pu l’exploiter moi-même au sein des opérations d’une fintech où on a fait exploser la productivité de l’équipe ops.
Pourtant, je reste personnellement frustré de ne voir que peu de démos d’usages concrets résolvant un process business dans son intégralité.
C’est justement l’objectif de cette newsletter hebdomadaire : partager des cas concrets d’automatisation par l’IA sur des business process basiques.
Pour cela, la structure de la newsletter se définit par :
un case study détaillé
les news de la semaine pour mieux cerner le champ des possibles à venir
les derniers outils IA (quick-win) qui peuvent faire gagner un temps précieux
un passage plus personnel sur ma réflexion sur l’IA
L’intro était un peu longue pour une première, c’était histoire de planter le décor et vous partager mon ressenti.
Case Study : Analyse de documents 📝
Plusieurs outils sont disponibles pour extraire des informations d’un document. L’un des outils les plus performants actuellement est développé par Anthropic et se nomme Claude. L’interface est similaire à ChatGPT.
C’est cet outil que nous allons utiliser pour nos cas d’usage. Nous allons distinguer :
les besoins ponctuels : la demande est faite par chat directement sur l’interface de l’outil
les besoins récurrents : on utilise l’outil par API depuis une autre interface et exploiter cette solution plus au cœur de nos process
Besoin ponctuel et basique
Exemple basique n°1 :
Un résumé d’un fichier volumineux et / ou des précisions sur certaines informations précises du document (donnée, éléments positifs ou négatifs du rapport, …).
Prompt basique : Je souhaite que tu me résumes les informations uniquement liées à l'intelligence artificielle dans ce rapport. Je souhaite une réponse concise sous forme de bullets points, chiffrée si possible.
Le document est en anglais et fait une centaine de pages.

Exemple basique n°2 :
Analyse sur plusieurs documents d’un produit financier sur une durée de plus d’1 an (ajout de 5 documents). L’objectif est de connaitre l’évolution du produit financier sur la durée

Sur ces demandes basiques, il est aussi pratique de modifier le prompt pour demander une extraction de certaines données sous un format spécifique (csv, json, etc) et l’exploiter plus facilement ailleurs.
Dans les exemples, j’ai utilisé des formats PDF pour l’analyse d’informations, mais on peut extraire les informations de documents en format :
PDF
documents texte : texte brut, doc, docx
Présentations Powerpoint (ppt, pptx)
image : jpg, png, jpeg, …
html
Fichiers markdown
Besoin récurrent et avancé
Pour les besoins récurrents, on va optimiser le prompt pour que le modèle soit plus performant.
Les prompts peuvent sembler anodins, mais leur optimisation permet d’optimiser drastiquement la performance. (voir cette étude réalisant des comparaisons sur les résultats en fonction des prompts)
Exemple avancé n°1 :
J’ai une liste de documents sur google drive, je souhaite extraire certaines informations chiffrés dans ces documents. Ils sont publiés tous les trimestres, je vais donc sortir de l’interface pour créer un process entier d’analyse de données.
Malheureusement, Claude et GPT ne permettent pas d’analyser un document depuis l’API. Je me suis pas mal cassé la tête sur le sujet pour trouver une solution et ça se passe sur Google Apps Script. (GAS)
Voici les étapes :
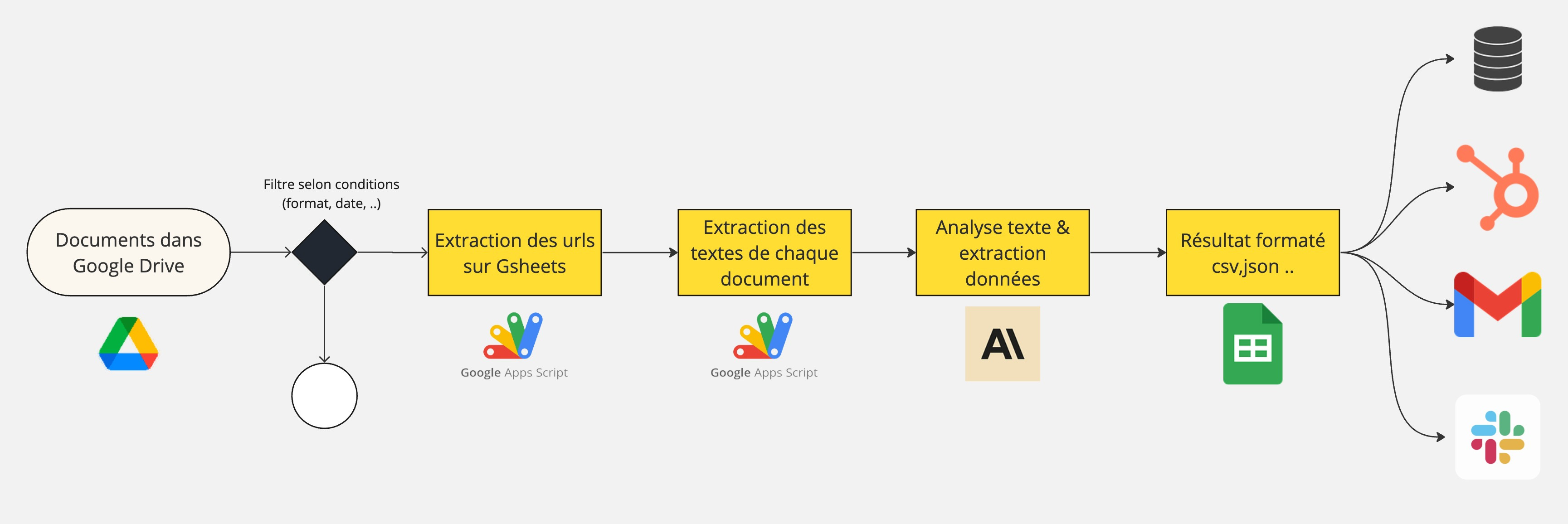
extraire les urls des documents de mon Google Drive sur une feuille “urls” sur Gsheets
extraire le texte de chaque document via l’ID présent dans chaque url sur une feuille “data” Gsheets
utilisation de l’API claude pour analyser et extraire des informations : formule Gsheets avec extension
une fois le résultat obtenu, les données peuvent être envoyées sur une base de données, CRM, mail, slack …
Après avoir ajouté mes documents dans un dossier Google Drive, le process me génère des informations précises de tous les documents.
Sur cette solution, l’IA générative est utilisée uniquement à la 3ᵉ étape car l’API n’est pas disponible pour traiter directement les documents. Le résultat obtenu par GAS n’est pas optimal et a ses limites, en lien avec la qualité de l’analyse du document fait par le script.
Petit aperçu du résultat sur une feuille gsheets. Dans cet exemple, je demande uniquement la valeur numérique comme résultat pour compléter une base de données.
Exemple avancé n°2 :
J’ai une série de facture / notes de frais. J’ai ajouté l’ensemble des documents dans un google drive depuis mon téléphone. Je souhaite extraire les informations suivantes :
date du document
nom de l’établissement
montant total
On utilise exactement la même procédure, le prompt est par contre modifié pour être plus résilient.
Tu es office manager, tu dois analyser rigoureusement les informations d’un texte et en extraire certaines. Les informations proviennent d’une analyse OCR, il est possible que certains éléments soient incorrects.
Pour éviter toute erreur d’analyse, tu devras :
- faire plusieurs analyses de texte pour confirmer la cohérence des informations. S’il y a une incohérence dans les informations, tu afficheras la valeur ‘Erreur de lecture’. Par exemple le total de la facture doit correspondre à la somme des montants.
- si tu ne nous trouves pas une information dans le texte après plusieurs analyses, tu afficheras la valeur ‘Erreur de lecture’. Ne donne pas de résultat si l'information n'est pas explicitement mentionnée dans le texte.
- si le contenu ne semble pas être une facture, une note de frais, un ticket, ou tout autre document ne correspondant pas à une dépense au sein d’une entreprise, tu afficheras la valeur ‘Erreur de lecture’.
Voici le texte : [INSERTION DU TEXTE]
Voici les informations à extraire avec uniquement les valeurs sans texte supplémentaire :
- date du document au format JJ/MM/AAAA
- nom de l’établissement
- montant total en ajoutant le symbole de la devise monétaire. Par exemple '€' pour l'euro. La virgule est utilisé pour afficher les décimales plutôt qu'un point.
Pas de texte supplémentaire en dehors du résultat au format CSV séparé par des points virgules
Un aperçu de ce que cela donne sur GSheets.
Il y a pleins de cas possibles sur l’extraction de données à partir de documents, n’hésitez à commenter si vous en avez d’autres ou besoins d’aide.
Vous pouvez retrouver les scripts Google Apps sur ce google docs si besoin.
Conseils 💭
Pour un besoin ponctuel, vous pouvez utiliser poe.com, comme interface qui permet d’utiliser des modèles différents dont Claude 3 gratuitement.
Pour l’utilisation d’une clé API et un besoin plus important, vous pouvez utiliser claude directement sur Anthropic et créer votre clé API depuis le dashboard, l’abonnement est à partir de 20€/mois. (Le service par API n’est pas accessible en France, il faudra utiliser un VPN).
Aller plus loin 🚀
Un scrapping des documents à analyser peut être mis en place en amont pour améliorer le process et stocker automatiquement tous les documents à analyser dans un espace partagé. Dès que de nouveaux documents arrivent sur le drive, l’extraction d’informations se lancerait.
Vous pouvez facilement programmer en fonction de votre besoin l’exécution du script. Par exemple dans le cas où vous souhaitez obtenir le résultat tous les lundis à 8h en utilisant les déclencheurs.
Les cas d’usages présentés dévoilent une petite partie de ce qu’il est possible de faire. En fonction de votre cœur de métier, les analyses de documents sont plus ou moins importantes. Un aperçu :
Finance et investissement : Analyse et résumé de produits financiers, surveillance de conformité, …
Juridique : analyse de contrats, recherche de jurisprudence, analyse de textes législatifs et réglementaires, gestion des risques légaux …
Immobilier : Comparaison de devis, analyse de baux, rapport d’AG …
RH : Analyse de CV, lettre de motivation ..
Pour sécuriser la qualité des données, une vérification en auto ou manuelle peut être mis en place et éviter l’hallucination du modèle. Pour cela, il est possible de mettre en place des gardes fous. Si la vérification par calcul, comparaison ou autre formule n’est pas possible, il faudra sûrement procéder à une relecture humaine.
Les limites ❌
Certains documents sont trop volumineux (pas possible d’analyser un document supérieur à 10Mo dans Claude 3). Les solutions possibles :
Utiliser des outils de compression peut aider à faire tomber le document sous les 10Mo
Diviser le document en plusieurs sections et procéder par étape dans l’analyse du document
Plusieurs documents peuvent être ajoutés en même temps, mais la limite est de 5 documents.
Certains documents ne sont pas lisibles. Pour cela, voici une solution :
J’utilise un outil comme Nanonets pour transformer le PDF en json, puis je demande à Claude de me faire un résumé.

Le rate limit de l’API peut rapidement bloquer une utilisation à l’échelle, j’en ai fait l’expérience lorsque j’ai réalisé une centaine de calls en parallèle sur des documents d’une dizaine de pages chacun.
Si vous avez des problématiques de confidentialité et sécurisation des données, Claude vous propose une alternative pour les gestions des données.
Certaines hallucinations sont possibles. La qualité du prompt est fondamentale dans la performance du modèle. Il ne faut pas hésiter à demander plusieurs fois le résultat en ajustant le prompt en conséquence.
Bilan
Claude-3 est l’outil le plus avancé du marché sur l’analyse de documents. Il est trés performant depuis l’interface utilisateur et la pertinence du résultat dépendra fortement du prompt envoyé. Cela reste un indispensable pour une personne manipulant des documents (même occasionnellement) étant donné le temps que cela peut faire gagner !
En ce qui concerne une utilisation plus “industrialisé” de l’outil, pour l’instant c’est compliqué pour plusieurs raisons :
l’API pour l’analyse de document n’est pas disponible directement, il faut passer par l’extraction texte du document par un outil tierce (comme l’OCR de Google Drive que l’on a utilisé).
Le rate limit de l’API pour des résumés de texte est vite atteint.
Ce n’est pas étonnant que l’outil est encore très peu utilisé dans des process complets en production comme le révélait une étude de A16Z.

Top news IA ☕
La nouvelle puce de Nvidia
Nvidia a une nouvelle fois frappé fort pendant sa keynote avec le lancement à venir de la puce blackwell. Cette puce a été conçu notamment pour améliorer les modèles d’IA, elle est 4x plus performante et 25x plus économique en consommation d’énergie, un enjeu important sur la durée.

C’est pas pour tout de suite (2025) mais cela promet de faire passer les modèles LLM dans une autre dimension en termes de calcul et donc de débloquer des nouveaux cas d’usages, surtout en ce qui concerne la création de vidéos. Ce type de création nécessite des calculs très importants.

L’entreprise confirme sa situation de quasi-monopole sur le marché des puces sur l’IA (2 000 milliards de valo début 2024) même si des initiatives venant de Google ou Amazon ont été lancé. L’écart risque de se creuser avec les modèles open-source.
La sortie de Devin
Cognition a présenté l’outil Devin : un développeur IA autonome. Capable de coder de manière autonome, de débugger et même de créer des sites web et des apps, Devin collabore avec les ingénieurs humains pour booster leur productivité ou fonctionne de manière autonome.
Ce qui est spétaculaire, ce sont les démos de l’outil qui ont été présenté. Cette démo montre que l’outil est capable de réaliser des missions complexes sur Upwork.
Actuellement, l’outil n’est pas ouvert à tous mais ce qui est intéressant, c’est la tendance à la spécialisation de certains outils sur des capacités précises (comme le développement web) et la performance que ces outils arrivent à atteindre en comparaison aux outils d’IA générative.
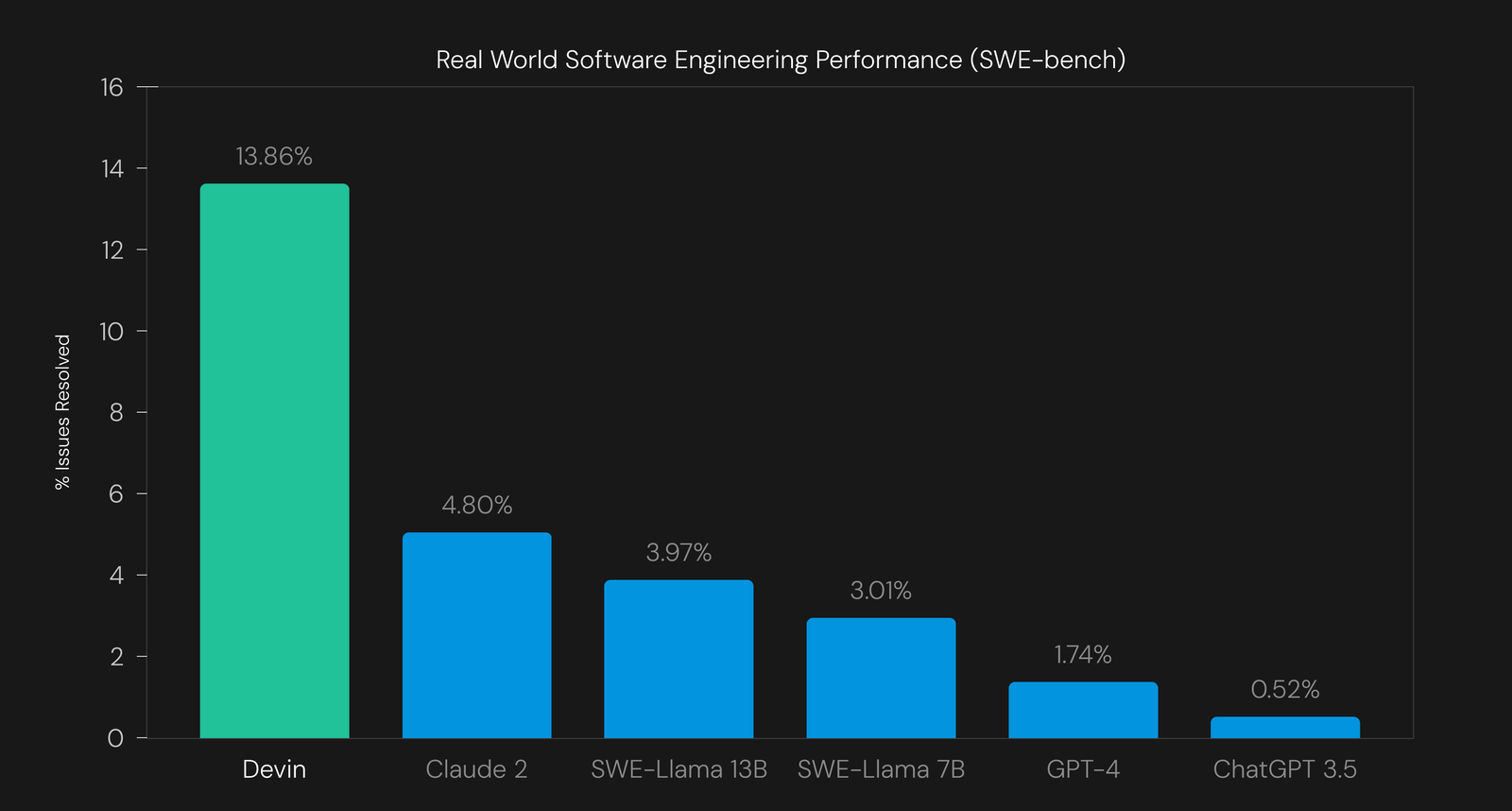
Ici, Devin réussit à résoudre 13,86% des problèmes soumis contre seulement 1,96% pour les modèles IA précédents.
Un aperçu fascinant du futur de la collaboration humain-IA dans la tech !
Apple compte intégrer de l’IA dans les prochains Iphone
Apple est en discussion avec Google pour intégrer l’IA générative (avec Gemini AI) dans son prochain système d’exploitation (iOS 18). En juin prochain, Apple devrait communiquer plus ouvertement dessus et l’annonce serait comme l’une mises à jour les plus importantes depuis le lancement de l’iphone.
Les cas d’usages depuis un simple téléphone pourrait être énorme et ça serait une avancée majeure pour ajouter l’IA à notre quotidien.
Des outils IA à vous partager ⚒️
Guidde - Extension pour de la création de documentation auto en interne
Une extension pour générer de la documentation en vidéo rapidement : tutoriels, FAQ, docs interne, nouvelles fonctionnalités, onboarding, présentation d’outils internes, ..
L’extension vous permet d’enregistrer votre écran et génère du contenu écrit avec les étapes de la vidéo et audio. C’est bluffant, super utile pour documenter vos process en interne.
J’ai fait un test basique et le résultat est top. Le voice over est un peu trop robotique mais le contenu écrit, les différentes étapes, la possibilité de supprimer / ajouter des étapes, éditer la vidéo, fait déjà gagner pas mal de temps.
Jetez un oeil à la vidéo pour être convaincu 👇
Retour d’expérience 👣
J’ouvrirais cette section la semaine prochaine pour ne pas allonger la longueur de la newsletter cette semaine.
C’est la première édition de cette newsletter, n’hésitez pas faire un retour sur le format et le fond 🙏
→ C’est super utile pour vous procurer la meilleure expérience de contenu possible.
Et si ça t’a plu, tu peux laisser un like sous l’édition
À très vite !